Database Design Project
Our task was to take data stored in an inefficient format and design a database to store it. I found it very useful to apply my learning to actual data with errors and unexpected anomalies. Moving this kind of inefficiently stored data into a structure database is a very common task for data scientists, so this experience will be very useful for future projects.
I used SQL to show the tables and their relationships, but actually an entity relationship diagram like this would have been a clearer format - I definitely learned from this for future projects.
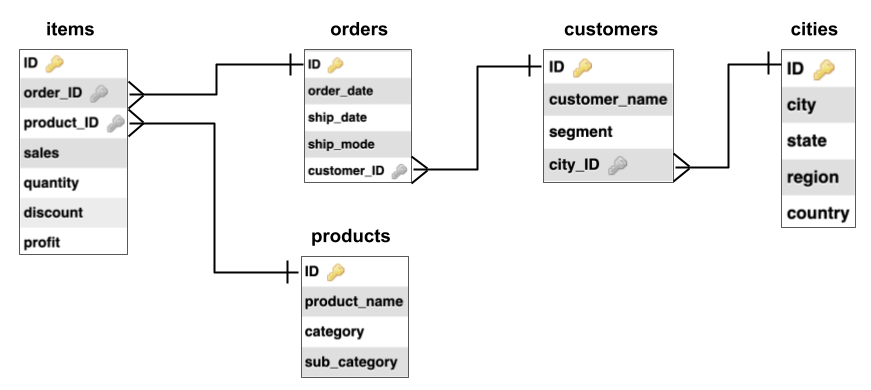
Here's my code for the Database Design Project. My team took sales data in spreadsheet form and converted it into a SQL database.
This Python code is for cleaning the data.
First the Python code lists unique values in the columns "Ship Mode", "Segment", "Country", "Region", "Category" and "Sub-Category".
import pandas as pd
df = pd.read_csv("superstore.csv")
df["Ship Mode"].unique()
array(['Second Class', 'Standard Class', 'First Class', 'Same Day'], dtype=object)
df["Segment"].unique()
array(['Consumer', 'Corporate', 'Home Office'], dtype=object)
df["Country"].unique()
array(['United States'], dtype=object)
df["Region"].unique()
array(['South', 'West', 'Central', 'East'], dtype=object)
df["Category"].unique()
array(['Furniture', 'Office Supplies', 'Technology'], dtype=object)
df["Sub-Category"].unique()
array(['Bookcases', 'Chairs', 'Labels', 'Tables', 'Storage', 'Furnishings', 'Art', 'Phones', 'Binders', 'Appliances', 'Paper', 'Accessories', 'Envelopes', 'Fasteners', 'Supplies', 'Machines', 'Copiers'], dtype=object)
The column "Product Name" contained some very long strings - this Python code finds the length of the longest string.
len(max(df["Product Name"], key=len)) 127
The columns "Profit", "Sales" and "Discount" were decimal values - this Python code finds the maximum number of decimal places in each column.
def decimal_places(d):
s = str(d)
return len(s) - s.find(".") - 1
decimal_places(max(df["Profit"], key=decimal_places))
4
decimal_places(max(df["Sales"], key=decimal_places))
4
decimal_places(max(df["Discount"], key=decimal_places))
2
This SQL code creates tables in the new database.
CREATE TABLE items (
ID int UNSIGNED NOT NULL,
order_ID varchar(30) NOT NULL,
product_ID varchar(30) NOT NULL,
sales decimal(20,4) NOT NULL,
quantity int UNSIGNED NOT NULL,
discount decimal(3,2) DEFAULT 0,
profit decimal(20,4) NOT NULL,
PRIMARY KEY (ID),
FOREIGN KEY (order_ID) REFERENCES orders(ID),
FOREIGN KEY (product_ID) REFERENCES products(ID)
)
CREATE TABLE orders (
ID varchar(30) NOT NULL,
order_date date NOT NULL,
ship_date date DEFAULT NULL,
ship_mode enum('Same Day','First Class','Second Class','Standard Class') NOT NULL,
customer_ID varchar(30) NOT NULL,
PRIMARY KEY (ID),
FOREIGN KEY (customer_ID) REFERENCES customers(ID)
)
CREATE TABLE products (
ID varchar(30) NOT NULL,
product_name varchar(150) NOT NULL,
category varchar(30) NOT NULL,
sub_category varchar(30) NOT NULL,
PRIMARY KEY (ID)
)
CREATE TABLE customers (
ID varchar(30) NOT NULL,
customer_name varchar(30) NOT NULL,
segment enum('Consumer','Corporate','Home Office') NOT NULL,
city_ID varchar(30) NOT NULL,
PRIMARY KEY (ID),
FOREIGN KEY (city_ID) REFERENCES cities(ID)
)
CREATE TABLE cities (
ID varchar(30) NOT NULL,
city varchar(30) NOT NULL,
state varchar(30) NOT NULL,
region enum('West','Central','East','South') NOT NULL,
country varchar(30) NOT NULL default 'United States',
PRIMARY KEY (ID)
)